
시작하기 전

I/O 멀티플렉싱 은 일반적으로 한 스레드에서 여러 논-블록킹 소켓(I/O streams)을 검사하여, 사용 가능한 소켓의 데이터를 처리하는 것을 의미합니다.(unix에서는 select나 poll, linux에서는 epoll을 생각하시면 됩니다.)
여기서 문제가 발생합니다. 한 스레드에서 처리할 수 있는 소켓은 한정되어 있다는 것이죠. 예를 들어보자면 10000개의 연결을 한 스레드에서 전부 처리하게 되면 부하가 집중되게 됩니다. 또 멀티코어 환경이라면 나머지 코어를 전혀 활용하지 못하는 매우 비효율적인 시스템이 될 수 있겠네요.
그럼 연결마다 스레드를 만들면 되지 않을까요? 스레드는 치명적인 단점이 무려 두 가지나 있습니다. 스택과 문맥 교환이죠.
스레드는 각자 별도의 스택을 가지게 됩니다. 이는 메모리가 스레드를 생성할 때마다 증가한다는 것을 의미합니다. 메모리는 데이터베이스등 다른 곳에서도 쓰일 곳이 많은데 이런 곳에 낭비할 순 없죠!
사실 이것보다 더 심각한 단점은 문맥 교환입니다. 모든 프로그램이 동시에 실행될 수 없기 때문에 운영체제의 스케쥴링 작업이 스레드(프로세스)를 프로세서에 눈 깜짝할 사이에 할당하는 것을 반복하게 됩니다.
그럼 프로세서가 다른 스레드로 전환될 때 작업이 완료되지 않은 프로세서에 남아있는 레지스터 값들과 같은 상태는 어떻게 될까요? 이 상태를 버리게 되면 스레드는 작업을 처음부터 다시 실행해야 됩니다. 따라서 운영체제는 이런 상태를 저장하고 나중에 복원하는 작업인 문맥 교환을 수행하게 됩니다. 앞서 말한 것처럼 문맥 교환은 프로세서의의 모든 상태를 저장하고 복원하므로 이러한 과정에서 오버헤드가 발생합니다. 당연히 스레드가 많아지면 많아질수록 문맥 교환은 더 자주 발생하게 되고 그만큼 오버해드도 늘어나게 되죠.
그래서. 보통의 서버는 멀티플렉싱과 스레드를 적절히 조율해 사용하고, 이 글에서는 I/O 멀티플렉싱을 하는 여러 개의 스레드로 서버/클라이언트를 구현한다고 가정해 보겠습니다.
근데 하나의 스레드에서 몇 개의 소켓을 검사해야 할까요? 스레드는 몇 개가 필요할까요? 그리고 이 스레드들을 어떻게 관리해야 할까요?
스레드 풀
먼저 스레드를 관리하는 방법을 알아봅시다.
위에서 말한 스레드의 단점 이외에 한 가지가 더 있다면 생성 삭제에 대한 비용입니다. 이런 비용을 줄이고 스레드를 편하게 관리하게 스레드 풀이라는 디자인 패턴이 널리 사용됩니다.
이름에서 연상이 되듯이 스레드 풀은 미리 생성된 스레드가 들어가 있는 풀을 의미합니다. 우리가 작업을 하고자 할 때 수영장에서 놀고 있는(대기 상태의) 스레드를 꺼내어 그 스레드에게 작업을 맞기는 것이죠. 따라서 스레드 풀을 이용해 스레드를 관리하면 각 작업에 대한 스레드를 만들 필요가 없어져 성능이 항상 될 수 있습니다.
스레드 풀은 성능 향상을 위한 목적 뿐만 아니라 task-based programming을 위해서도 사용됩니다. 이러한 시스템은 스레드를 추상화므로 매우 많은 비동기 작업을 처리하는데 있어 전통적인 스레드 기반 시스템보다 효율적일 수 있습니다. task-based programming을 사용하면 각 소켓마다 작업을 추가하면 되므로 프로그래밍이 매우 쉬워집니다.
<실습> task-based programming 하기
스레드 풀을 직접 구현하는 것은 이 글의 범위를 벗어나므로 task-based programming만 간단히 실습 해봅시다. task-based programming를 하는 방법은 여러가지가 있지만, 가장 쉬운 방법은 표준 라이브러리를 사용하는 것입니다. C++에서는 std::async을 통해 할 수 있습니다. 사용 방법도 매우 간단합니다.
주의할 점은 std::async는 새로운 thread에서 실행되는 것을 보장하지 않습니다. 따라서 std::launch::async을 사용하여 항상 새 thread에서 실행되게 해야 합니다.
#include <future> auto returnVar = std::async(std::launch::async, func, parameter...); //func 함수를 비동기적으로 실행
std::async는 std::future라는 객체를 반환하게 되는데, 이 객체로 비동기로 수행된 함수의 반환 값에 접근 할 수 있습니다. 또 wait, wait_for, wait_until을 사용해 객체에 접근 가능할 때까지 대기할 수 있습니다.
returnVar.wait(); // 객체에 접근 가능할 때까지(함수가 종료될 때까지) 무한정 기다립니다.
#include <chrono>
do{
auto status = returnVar.wait_for(std::chrono::seconds(seconds)); // 주어진 시간만큼 기다리며 상태를 반환합니다.
//...
} while (status != std::future_status::ready);
// 접근이 가능해지거나 시간을 초과하면, status의 값이 std::future_status::ready가 됩니다.
auto futureStatus =
returnVar.wait_until(std::chrono::system_clock::now() + std::chrono::seconds(2));
// 주어진 시간만큼 대기하고, std::future_status를 반환합니다.
// 위에 제시된 wait중 하나만 사용하면 됩니다.
auto getReturnVar = returnVar.get(); // 반환 값을 가져옵니다.
//...
std::async보다 잘 알려진 라이브러리들 중 하나 인 TBB(Threading Building Blocks)를 사용하시는 것이 좋습니다.– 스레드의 개수
그런데 스레드 풀의 스레드들의 개수를 어떻게 조절해야 할까요? 저는 프로세서 개수 만큼의 스레드을 사용하는 것을 선호합니다.
I/O는 실제로 프로세서 내부에서 일어나는 작업이 아니기 때문입니다. I/O 장치는 프로세서 사이클보다 느립니다.
프로세서가 I/O를 처리하는 방식 중 하나 인 인터럽트 기반 I/O로 예를 들어보자면, CPU는 I/O 컨트롤러에게 I/O 장치에 대한 신호를 보낸 다음 I/O 컨트롤러가 인터럽트를 발신 하기 전까지 해당 I/O 작업에 대한 추가적인 작업을 할 수 없습니다.
따라서 I/O 작업이 CPU 집약적인 작업이 아니기 때문에 프로세서 개수 이상의 스레드가 불필요하다는 것이죠.
<실습> 프로세서 의 개수 얻기.
C++11 이후로 hardware_concurrency()를 사용해서 얻을 수 있습니다.
#include <thread> auto n = std::thread::hardware_concurrency(); // processor 의 개수를 반환
멀티플렉싱
스레드를 어떻게 관리할지, 개수는 어떻게 할지 알아보았으니 멀티플렉싱을 알아봅시다!
서버에서도 멀티플렉싱이 필요할까요? 사실 소켓통신에서 클라이언트와 서버의 작동 방식은 크게 다르지 않습니다. 단지 listening 소켓의 유무일 뿐이죠. accept로 요청을 수락하면, 해당 연결에 대한 소켓이 새로 생성됩니다. 이러한 소켓들을 모아 멀티플렉싱하는 것이죠.
– 논-블록킹 소켓
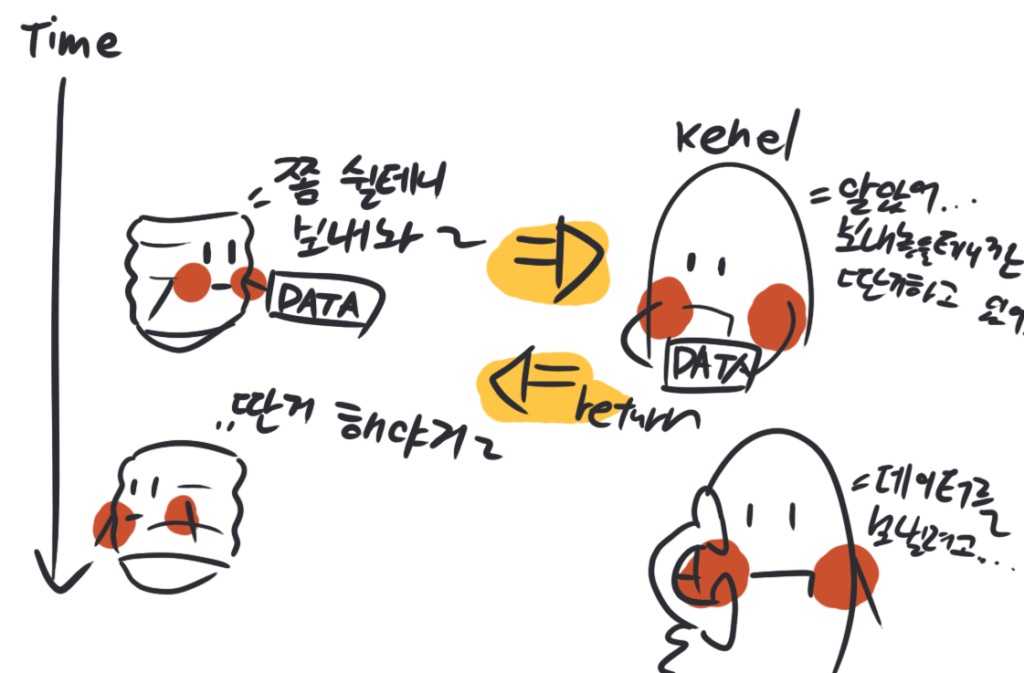
멀티플렉싱을 하기 위해서는 일반적인 블록킹 소켓 대신 논-블록킹 소켓을 사용해야 합니다. 왜 논-블록킹 소켓을 사용해야 할까요?
논-블록킹 소켓은 말 그대로 차단하지 않는 소켓입니다. 이러한 소켓에 대한 I/O작업은 작업이 완료되지 않더라도 무조건 먼저 반환이 됩니다. 예를 들어 논-블록킹 소켓을 사용하게 되면 어떤 데이터를 전송하고자 할 때 전송이 완료될 때까지 기다리는 것이 아닌 무조건 반환 되고, 커널이 해당 전송 작업을 수행하게 됩니다. 마찬가지로 어떤 데이터를 수신하고자 할 때 데이터가 올 때 까지 기다리는 것이 아닌 데이터가 준비 되었을 때 해당 데이터를 가져옵니다.
따라서 I/O 작업이 완료되지 않더라도 다른 작업을 수행 할 수가 있게 되면서 여러 소켓들을 검사할 수 있기 때문에 논-블록킹 소켓을 사용해야 합니다. 만약 블록킹 소켓을 사용하면, 한 소켓에 데이터가 올 때까지 계속 대기하느라 다른 소켓의 처리가 지연되겠죠!
<실습> 논-블록킹 소켓 생성.
대부분의 운영체제에서 호환되는 인터페이스인 POSIX를 사용하여 생성해 봅시다. 먼저 소켓을 생성합니다.
#include <sys/socket.h>
auto Socket = 0;
if(Socket = socket(PF_INET,SOCK_STREAM, IPPROTO_TCP); Socket == -1){
return false;
}
SOCK_NONBLOCK를 사용하여 논-블록킹 소켓으로 바로 생성할 수 있지만, 이전 버전 호환성을 위해 fcntl()을 사용하여 블록킹 소켓을 논-블록킹 소켓으로 바꿔줍니다.
#include <fcntl.h>
if(fcntl(Socket, F_SETFL, fcntl(Socket, F_GETFL, 0) | O_NONBLOCK) == -1) {
::close(Socket);
return false;
}
– Polling
데이터를 전송할 때는 몰라도, 데이터가 준비된 것을 어떻게 알고 가져올까요? 데이터가 준비됐는지 확인하려면 커널에게 지속적으로 준비 상태를 물어봐야 합니다. 이렇게 상태를 지속적으로 감지하는 것을 polling이라고 합니다.
I/O polling은 성능의 이유로 대부분 운영체제에게 맡기게 됩니다. 대표적으로 poll등이 있겠네요. 이 부분에 대한 더 상세한 동작을 알고 싶으시면 이 글을 참고해 주세요! (외부 링크)
이벤트 처리 패턴
I/O에서 스레드 풀은 보통 단독으로 쓰이기 보다 이벤트 처리 패던들과 같이 쓰입니다. 대표적인 이벤트 처리 패던은 reactor 패턴과 proactor 패턴이 있습니다.
먼저 reactor 패턴에 대해 알아보겠습니다. 이 패턴은 아래 사진에 보이는 다이어그램으로 간단하게 설명할 수 있습니다.


