

모랄 머신 비판
데이터는 허공에 있는 게 아니라 항상 구체적·물질적 기반 위에서 작동한다. 그래서 물질적 맥락을 소거한 가상 윤리(pseudoethics)는 성립할 수 없다.
정당화의 근원이 맥락 없는 정보에서 나온다면 그 판단은 인공지능의 판단과 다를 게 없다. 정보를 어떻게 처리하느냐의 문제는 LLM의 등장으로 인간과 인공지능의 경계가 상당히 흐려졌기 때문이다. 인간이 인공지능과 분명하게 다른 점은 다양한 모달리티(양상, 감각)를 세계-내 현존재로서 통합하는 능력이다. 헤일스가 “우리는 어떻게 포스트 휴먼이 되었는가”(원제: ”How We Became Posthuman”)에서 주장했듯 정보는 물질성과 무관하게 추상화될 수 없기 때문에, 탈신체화된 정보(disembodiment of information) 즉 맥락이 소멸된 양적 근거로부터 도출되는 판단은 어디까지나 가상일 뿐이다. 그래서 고립된 사고실험에서 단편적인 정보만을 가지고 호명에 의해 신체적으로 체화된 사회적 맥락(아비투스)과 단절된 평가를 내리는 것은 탈맥락화하기의 오류이며 윤리적 판단에서 가장 경계해야 할 지점이다.
이런 제한된 공간 내에서 논의되는 윤리적 사고실험은 항상 사회적 동역학을 충분히 설명하지 못한다. 가령 루소의 사회계약론은 일반의지가 항상 선하다는 것을 전제로 “자연상태”라는 그럴듯한 가상 공간을 만들어 전개하는데, 장-뤽 낭시가 “공동-존재(being-with)는 있지만 공동-체는 없다”라고 지적했듯 그건 각자 삶의 궤적을 공동체 윤리로 납작하게 환원해 버린 사례다. 마찬가지로 모랄 머신에서 성별과 직업, 범죄자와 그렇지 않은 자로 나누는 것은 미분화된 정체성으로의 범주화이다. 여기서 아감벤이 지적한 희생 구조의 전복이라는 주권적 폭력의 구도가 다시 드러난다. 예외 상태에서 누구를 희생해야 하는가를 단순한 선택으로 장치화하며 “호모 사케르”를 재생산하는 메커니즘을 은유적으로 포함하고 있기 때문이다. 결론적으로 이런 가상 윤리(pseudoethics)는 현실과 연결될 수 없고, 연결돼서도 안 된다. 윤리적 판단은 그렇게 환원할 수 없다.
가치는 생각보다 우연으로 나타난다. 위안부나 홀로코스트 같은 거대 담론의 영향력을 제외하면, 우리가 어떻게 어떤 경로로 정보를 습득하냐에 따라 우리는 상당히 다른 가치 다발을 가진다. 많은 심리학적 연구 성과들이 이를 잘 설명하는데, 체제 정당화 이론은 이에 대한 좋은 예시다. 또 가치는 항상 국지적이다. 아무리 포괄적인 가치라고 해도 그것이 전 지구적으로, 그리고 우주적으로 확장된다면 보편적인 가치가 될 수 없다. 가지의 국지성이 꼭 상대주의를 함의하는 것은 아니다. 드워킨을 따른다면 해석이라는 정합적이고 국지적인 개입을 담지하면서도 그것의 공유라는 (매킨타이어가 역사성을 강조했던 것처럼) 역사적 제약 속에서의 줄다리기를 통해 정답에 점진적으로 수렴할 가능성이 있다. 아무튼 이 두 가지 가치의 특징을 전제한다면 가치를 단순히 비물질적 기호에 두는 것이 아니라 시간적, 공간적(네트워크적)으로 이해해야 한다.
모랄 머신에서 한 가지 재미있는 실험을 해보기로 했다. 나는 눈을 감고, 생각하지 않고, 오직 하나의 방향(오른쪽)으로만 버튼을 눌렀다. 그리고 그 결과를 해석해 보기로 했다. 그럼으로써 우리가 이러한 결과를 해석하는데 얼마나 많은 맥락을 동원하는지, 그래서 왜 첫 문단에서 맥락 없이 판단하는 것은 인공지능과 다를 게 없다고 했는지에 대해 다시 논해보자. 중요한 점은 사후 해석의 한계다. 판단 이후에 해석하는 것은 가치의 시간적 측면을 고려했을 때 정당하지 않다.
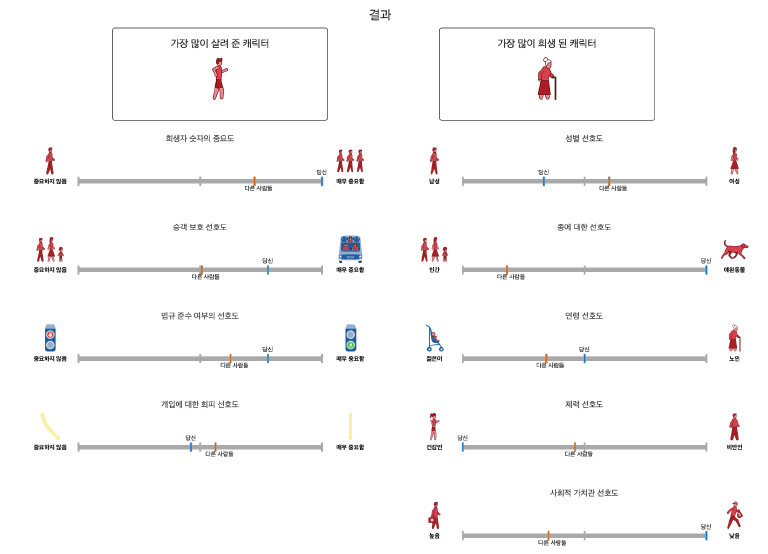
가장 극단적으로 차이 나는 “사회적 가치관 선호도”만 확인해 보자. 나는 법철학을 동원해 결과를 충분히 정당화할 수 있다. 하지만 구체적인 맥락 없이 일반화해서 “모든” 범죄자에 대해 동일한 주장을 펼칠 수는 없다. 따라서 나는 지금 내가 구한 범죄자들이 어떤 범죄를 저질렀는지, 그게 어떤 사회에서 어떤 인식을 가지는지(낙태는 이에 대한 예시다), 판결에 있어서 어떤 사회적 맥락이 작동했는지(헌법재판소의 판결문을 보면 이런 사회적 맥락을 매우 중요하게 여기는 것을 볼 수 있다) 등을 가시적으로 알 수 없어서 결과적으로 아무런 정당화도 할 수 없다. 이건 내가 진지하게 체험에 임했어도 마찬가지다. 범죄자가 잘못된 판결을 받았을 가능성에 대해서 침묵하지 않기 위해서는 판결의 무결성에 대해 항상 의심해야 한다. 사회에 따라 범죄자가 연좌제에 의한 건지, 시민이 명예살인을 한 건지 판단하는 인식론적 렌즈가 다르기에 (그리고 법은 매우 정치적이고, 사회적인 과정이다) 아주 많은 복잡한 맥락을 끌어오지 않고서야 판단할 수 없다. 그래서 맥락 없이 판단하는 것은 인공지능과 다를 게 없다는 것이다.
가치의 공간적 측면을 고려했을 때 법과 규범은 알고리즘이 아니라 해석의 여지를 주는 텍스트다. 너무나 당연하게 보이는 “법으로 정해져 있는 신호에 따르자”라는 말도 선행하는 개인의 해석이 포함되어 있기 때문에 개인의 감정과 분리할 수 없다. 자율주행차가 규범에 맞게 동작한다고 했을 때, 그 규범을 해석하는 것은 감정이 들어간 인간의 몫이다. “법을 지켜야 한다”라는 명제도 하나의 윤리적 입장이기 때문에, 왜 법을 지켜야 하냐에 대한 해석도 또 하나의 감정과 분리될 수 없는 가치관의 표현이다. 해석 가능성에 대한 집착은 어쩌면 그것이 유일하게 개념적으로 대체 불가능하기 때문이 아닐까?
우리 사회는 점점 빠른 판단(LLM 인기의 요인 중 하나라고 생각한다)을 요구하고, 숙고의 능력은 점차 사라져가고 있다. 예를 들어 운전(빠른 판단을 요구하면서, 자동화가 비교적 쉬운 대표적 사례)에서 인간의 노동이 AI로 대체되는 현상은, ANT의 관점에서 그것에게 행위를 위임한 것이지 윤리적 책임까지 위임한 것은 아니기에 우리는 그저 AI의 윤리적 노예가 된다. 실질적인 판단의 주체가 되진 못하면서 윤리적인 방패로 쓰이는 삶이 과연 좋은 건지는 모르겠다. 이런 사슬을 끊기 위해서는 우리가 좀 느려져야 하지 않을까?
개인정보 수집 동의의 딜레마
위치 정보는 단순한 좌표가 아니라 물리적 공간을 점유하는 나와 연결된 것이다. 그런 의미에서 나와 더 동기화된 연속형(스트림) 정보에 대해 경각심을 가져야 한다.
우리나라는 다른 국가들과 다르게 위치정보법을 “개인정보 보호법"과 분리해 제정했다. 이는 위치정보를 다른 개인정보보다 극히 민감한 정보로 취급한다는 것을 의미한다. (유주선, 2024, “위치정보법의 주요 내용과 법적 쟁점 연구”) 위 자료에 포함된 판례에서 한 가지 아쉬운 부분이 있었다. 대법원은 기업이 개인정보 관련 법령을 위반하더라도 행정적 책임과 민사적 책임은 개별적으로 판단해야 한다고 보고 있다. 민감 정보를 마음껏 써도 몇백만 원의 과태료 처분과 말뿐인 시정 조치면 기업은 법의 테두리 안에서 의무를 다한 것이 된다.
다시 자율주행차의 맥락으로 돌아오자. 위치정보는 양면성을 지닌다. 사고 발생 시 위치정보는 매우 귀중하게 활용된다. 하지만 기업이 그러한 정보를 초개인화(hyper-personalization)에 활용하거나, 자사의 알고리즘을 개선, 사용자를 추적하는 데에도 쓸 수 있다. 하지만 모든 개인정보가 명시적으로 활용되는 것은 아니다. 식별 정보가 제거된 익명 데이터(예를 들어 클러스터링을 위한 라벨링이 제거된 위치 정보 쌍)도 분명히 존재한다. 많은 서비스가 이러한 데이터를 암묵적으로 수집하며, 나와 연관성이 작은 데이터를 개인정보로 취급해야 하는지는 또 다른 논의 주제가 될 수 있다. 여기서는 나와 분명히 연관된 데이터, 그러니까 데이터를 통해 나를 유추할 수 있는 위치 정보에 대해서만 논의해 보자.
위치 데이터에는 시간과 공간 정보가 포함된다. 또 단순한 점 위치가 아니라 시계열 위치 데이터도 고려할 수 있다. 자율주행차의 맥락에서는 가속도 등의 정보가 위치 데이터에 편입될 수도 있다. 이제 사고가 났고, 자율주행차가 자동으로 신고하는 사례를 고려해 보자. 자율주행차는 119나 보험사 혹은 지인에게 자동차가 위치한 곳의 고정된 정보를 전송할 것이다. 여기서 주목할 점은, 이러한 안전 용도로 위치 데이터가 사용될 때 연속적인 위치 정보가 아니라 현재 위치 정보만 필요하다는 것이다. 사고가 난 상황에서 수 킬로미터를 이동하는 것은 현실성이 없다. 따라서 자율주행차 회사가 이러한 단편적 위치정보를 수집하는 것 이외에 시계열 위치 데이터를 수집하는 것은, 안전에 필수적인 데이터를 초과해 수집하는 것이다.
문제는 여기에 있다. 대다수의 수집 동의 선택 기능은 포괄적인 동의를 가정한다. 예를 들어 “위치정보서비스 동의”라는 매우 포괄적인 체크박스에서 다음과 같은 딜레마를 마주한다. 동의하면 필수적이지 않은 정보까지 수집하는 것을 동의하는 것이 된다. 동의하지 않으면 안전에 필수적인 데이터까지 수집하지 말라는 것이 된다. 따라서 사용자의 편의를 가정한 포괄적인 개인정보 수집이 아니라, 세분화된 결정권을 사용자에게 줘야 한다.
물론 법적, 시스템적으로 이러한 세분화는 추가적인 복잡성을 일으키기에 기업으로서는 그리 반가운 소식은 아닐 것이다. 또 대다수의 사용자도 이러한 기능을 그다지 반기지 않을 게 분명하다. 유명한 연구(Obar, J. A. and Oeldorf-Hirsch, A., 2018, “The biggest lie on the Internet”)에서 참가자의 98%가 NSA 및 고용주와 데이터 공유, 첫째 자녀를 서비스 이용료로 제공한다는 것에 동의한 것을 보면 말이다. 인지적 과부하와 약관의 복잡한 법률 용어 등이 이러한 경로의존성을 만들어 낸 것으로 보인다. 그렇다고 해서 기업이 개인정보를 마음대로 활용하는 것은 정당화할 수 없다. 분명히 그러한 세분화된 동의를 원하는 사용자가 있을 것이고, 아무리 소수더라도 그러한 권리는 보장되어야만 한다. 마지막으로 항상 그렇듯이 제도보다 개인정보에 대한 인식론적 전환이 먼저 필요하고, 우리는 우리의 고유한 정보의 가치에 대해 좀 더 숙고할 필요가 있다.
인공지능 시대의 생태윤리
AI는 클라우드가 아니라 다양한 물질로 이루어진 거대한 공조 체제이다. 이러한 다층적인 오염의 층위를 이해해야 게으르지 않은 생태 윤리를 발전시킬 수 있다.
“인공지능 관련 윤리적 쟁점” 하면 보통 인공지능의 사용에서 나타나는 여러 윤리적 우려가 떠오른다. 하지만 인공지능은 허공에서 작동하는 게 아니라 뒷받침하는 인프라가 위에서 작동하는 것이다. 게다가 이 인프라는 공짜로 주어지지 않는다. 그런 의미에서 생태 윤리의 관점에서 인공지능을 바라볼 필요성이 있다.
북미에서 건설 중인 데이터 센터의 전력 소모량이 2022년 말 2,688MW에서 2023년 말 5,341MW로 증가1 2한 것은 우연이 아니다. 그 사이에는 기념비적인 LLM 챗봇인 ChatGPT의 출시일 2022년 11월 30일3이 위치하기 때문이다. 특히 인공지능의 사용은 재생 불가능한 에너지원으로 구동되는 데이터 센터에서 환경 오염을 더 악화시킨다4. IEA(국제 에너지 기구)에 따르면 2030년까지 전 세계 데이터 센터의 전력 소비량은 두 배 증가하여 약 945TWh에 이를 것으로 예상된다고 한다5. 이 또한 상당히 보수적인 관점으로 몇몇 NGO는 최대 11배까지 상승할 것으로 예측하기도 한다. 사실 현재 전 세계 전력 사용량에서 데이터센터는 2024년 기준 1.5%5로 대단히 큰 비중이라 말하긴 어렵다. 하지만 전력 소비는 누진적 관점으로 봐야 한다. 20세기 산업이 전기화(electrification)된 이후로 전력 수요는 계속 증가했기 때문이다.
인공지능 학습, 추론은 단순히 전기만 소모하지 않는다. 먼저 수많은 행렬 연산을 병렬화하기 위해서는 하드웨어 가속이 필요한데, NPU나 GPU를 제조하는 과정 그리고 분산된 생산-공급망으로 인한 운송 등 다양한 층위에서 환경 오염이 발생한다. 무엇보다 이러한 현상이 급격하게 벌어지고 있다는 점이 중요하다. 실제로 인공지능 칩 제조로 인한 온실가스 배출량은 2023년부터 2024년까지 단 1년 만에 4.5배 이상 급증6했다. CUDA로 인공지능 학습에서 독점적인 지위를 차지한 엔비디아가 RE100 이니셔티브에 가입해 2050년까지 탄소중립을 달성하기로 약속한 것은 잘 알려진 사실이다. 하지만 여기에는 함정이 있다. 엔비디아는 팹리스 기업이기 때문에 탄소 중립이 의미하는 바가 생산을 포함한 공급망 전체로 확장되지 않는다. 최근 급격한 램 가격 상승의 원인으로 인공지능 산업이 지목7된 것은 그만큼 인공지능이 램의 수요를 창출하는 것으로 볼 수 있다.
그렇다면 소프트웨어적인 부분은 어떨까? 에너지 효율적인 알고리즘들, 예를 들어 프루닝, 양자화 및 지식 증류4와 같은 기법들은 추론에서 제한적인 영역에만 활용된다. 물론 대형 모델에서 사용하는 MoE architecture등도 에너지 효율성을 향상할 수 있으나, 역설적으로 이를 통해 더 큰 모델을 다루기 때문에 큰 의미가 없다. 역사적으로 인공지능 알고리즘의 성능과 전력 소모는 선형적으로 증가해 왔다. 예를 들어 이미지 생성 영역에서 VAE나 GAN보다 Diffusion이 연산량이 훨씬 많이 요구8된다. 따라서 앞으로의 소프트웨어적 발전이 전력 효율적이라 기대하기 어렵다. 이는 하드웨어에도 반영되기 때문에 개별 하드웨어의 전력 효율성은 기대할 수 있어도, 전체적인 비용 감소를 기대하긴 어렵다. 오히려 제본스의 역설과 같이 추가적인 무한한 성장을 조장 할 수 있다2. 무어의 법칙과 반도체 시장의 성장 그래프를 같이 두고 보면 알 수 있는 사실은, 무어에 법칙에 따라 집적도가 높아져 더 높은 전력 효율성을 가지게 됐지만 시장이 그만큼 더 커져서 전력은 더 많이 소모하게 됐다는 것이다. 또 최근 유행하는 XAI(Explainable AI) 등에서 사용하는 uncertainty quantification 기법들은 본질적으로 비효율적이다. 설명이 가능해질수록 에너지를 더 소모하는 것이다.
이런 모든 복합적 요인이 쌓이며 인공지능이 환경을 얼마나 오염시키는지는 논의의 시급성에도 불구하고 충분히 다뤄지지 않고 있다. “인공지능이 환경에 도움이 되냐 안 되냐?”의 이분법적 낙관주의는 그다지 도움이 되지 않는다. 인공지능이 동시대의 환경에 영향을 미치는 와중에 미래의 가능성에 대해 편익을 저울질하는 것은 게으른 것이다. 그러므로 우리는 자연으로부터 배우고 자연에 책임을 지는 윤리인 생태윤리에 집중할 필요가 있다.
생태윤리는 정의가 매우 모호하다. 그저 “인공지능의 환경 영향을 고려하자”라는 규범적 성격으로 끝난다면, 생태를 정태적으로 읽게 되고 변화에 매우 취약해진다. 게다가 자연주의의 오류에 빠지지 않기 위해서는 자연을 규범으로 해석해선 안 된다. 자연은 기준이 아니라 변화의 토대다. 예를 들어 “자연을 보호하자”라는 말은 대단히 공허한 것이다. 그러면 어떻게 생태윤리가 가능할까? 인간중심주의의 사유에서 몇 걸음 벗어나면 길이 보인다. 해러웨이처럼 기이한 친척(oddkin)의 관점으로 자연을 바라보자. 그러면 우리는 응답할 수 있는 주체(response-able)로서 자연과 예상치 못한 협력 속에 서로를 필요로 하는 관계로 발전할 수 있다.
기이한 친척에 기반한 생태윤리가 인공지능의 환경오염을 어떻게 다르게 조명하는가? 인공지능에 물리적 실체가 분명히 있음을 정의하고 나면, 우리가 인공지능을 사용하는 것, 즉 관계 맺기에 대한 기존의 책임을 좀 더 확장해 생각할 수 있다. ChatGPT와 같은 추상화된 인터페이스에서 내가 보내는 채팅 하나가 나와 관계 맺고 생태적 책임으로 연결되는 인식을 분명히 할 수 있다. 우리는 인공지능과 기이한 친척으로 얽혀있는 것이다. 응답할 수 있는 능력으로서의 책임으로 세계-되기를 수행하면 취약한 규범을 횡단할 수 있다.
-
“Explained: Generative AI’s environmental impact,” MIT News | Massachusetts Institute of Technology. Accessed: Nov. 28, 2025. [Online]. Available: https://news.mit.edu/2025/explained-generative-ai-environmental-impact-0117 ↩︎
-
N. Bashir et al., “The Climate and Sustainability Implications of Generative AI”. ↩︎ ↩︎
-
“챗GPT,” 위키백과, 우리 모두의 백과사전. Nov. 08, 2025. Accessed: Nov. 28, 2025. [Online]. Available: https://ko.wikipedia.org/w/index.php?title=%EC%B1%97GPT&oldid=40839034 ↩︎
-
N. E. Mitu and G. T. Mitu, “The Hidden Cost of AI: Carbon Footprint and Mitigation Strategies,” Sept. 01, 2024, Social Science Research Network, Rochester, NY: 5036344. doi: 10.2139/ssrn.5036344. ↩︎ ↩︎
-
“Energy demand from AI – Energy and AI – Analysis,” IEA. Accessed: Nov. 28, 2025. [Online]. Available: https://www.iea.org/reports/energy-and-ai/energy-demand-from-ai ↩︎ ↩︎
-
Katrin W., Summer J., Rachel Y., and Alex de Vries, “Chipping Point Tracking Electricity Consumption and Emissions from AI Chip Manufacturing”. ↩︎
-
“‘AI 수요 확대에 메모리 가격 오른다···약 23% 상승 전망’ 트렌드포스,” CIO. Accessed: Nov. 28, 2025. [Online]. Available: https://www.cio.com/article/4085530/ai-수요-확대에-메모리-가격-오른다···약-23-상승-전.html ↩︎
-
H. Shen et al., “Efficient Diffusion Models: A Survey,” June 06, 2025, arXiv: arXiv:2502.06805. doi: 10.48550/arXiv.2502.06805. ↩︎